Press Release 08/23/2021
PRESS RELEASE
Ground-Breaking Invention in Batch Processing Technology
Considerably less expensive and over 20 times faster than legacy systems
The long-awaited solution for the legacy migration dilemma has finally arrived! A Maryland-based company, KeyGen Data LLC, revealed a revolutionary invention poised to reshape the batch processing sector.
With rapid advancement in speed and security, cloud-based systems are successfully performing transaction-based processing and transitioning from the legacy mainframe platforms. However, large-scale batch processing applications are significantly limited in performance when migrated to the cloud. Current cloud-based solutions are severely inefficient in processing batch systems when large amounts of data and complex processing are involved. This single issue has been hindering full migration from legacy platforms into cloud-based systems, forcing companies to continue the high cost of their mainframe investments to support their batch processing needs while moving only online transaction processing (OLTP) systems to cloud. This results in 40–60% of their processing needs being retained on the mainframe.
To address this challenge, KeyGen developed a new processing method called HyperBatch. This newly available method treats batch data, or sequential data, as horizontal layers within a set of keys. Currently available methods treat batches as vertical layers, while implementing a top-to-bottom approach. This new concept of data processing allows the batch program to process millions of layers of data simultaneously against batch processing business rules. This introduces opportunities for new research and development in this area.
HyperBatch renders the “cursor” processing option available in all relational database management systems (RDBMSs) obsolete, as the new process delivers hundredfold performance gains and ease of code conversion for complex rules. Large legacy systems have millions of rows to process in a batch system on a daily, weekly, or monthly basis. The cost of running such large systems is vast in terms of resources and money, along with demanding a great deal of time.
The HyperBatch process has demonstrated performance gains over 20 times faster than the mainframe solutions and at a significantly lower operating cost. This creates opportunity for businesses to run a monthly, weekly, or even daily batch, delivering more up-to-date data for reporting and analytics.
To achieve such tremendous gains via the HyberBatch method, a fundamental shift in the view of data in a sequential or flat file system from exiting methodologies was followed. The new HyperBatch approach will not only help develop more robust applications, but it will also help in the development of many new tools to support the effort to migrate to the new method. KeyGen Data has applied for multiple patents in support of this technology and has just been awarded its first patent on the technology.
As the industry adopts the HyperBatch method, cloud vendors such as AWS, Azure, and Google Cloud should see a boost in migration of legacy systems to their platforms. Massively parallel processing (MPP) capability on their platform will enable horizontal processing of sequential data via the HyperBatch method. Flat file-based data storage will also be replaced by new MPP-capable databases, and all flat file processing will be done in MPP-based horizontal processing methods. This will enable scalability in batch processing to meet growing demand and make possible the ability to perform more frequent batch runs at much lower costs and resource utilization. Moreover, the advancement of processing power available in cloud environments and the scalability makes it ideal for HyperBatch processing. Standalone servers at client sites can also accomplish the same goal if MPP-capable databases are available.
Currently available legacy migration solutions to the cloud such as code refactoring do not incorporate or employ any new methods for tackling the core issue of batch processing: data being processed one row at a time. They simply convert the system to another programming language or another hardware without addressing the core problem. These solutions can be very successful at transitioning transactional systems—but fail when batch is part of the requirement. Current methods of batch processing do not translate well to the cloud environment, resulting in a massive reduction in performance and complex and costly strategies to minimize the loss.
Conversions leveraging the HyperBatch method involve a redesign of the existing process based on the business logic. The process (and code) will be simpler and much easier to maintain, while also producing 80% less lines of code than the original system. Presently, no automatic tool is available for this conversion. This option is currently being researched, and partnerships are being explored with code refactoring vendors that can incorporate the HyperBatch method into their tools.
The cost of running the HyperBatch process after conversion is much less than the cost of the conventional methods. It substantially outperforms the Mainframe and does not require explicit sorting of the data which traditionally adds a significant load to the batch process overall time. Although a
20–60× performance improvement over the mainframe is considerable, HyperBatch has also demonstrated performance improvements as much as 160 times over the fastest non-mainframe RDBMS-based solutions. HyperBatch offers big opportunities for cloud vendors to meet migration needs by completely eliminating the current batch process performance issues.
Traditional RDBMS will also benefit by integrating the HyerBatch method into toolsets that support their MPP capabilities. Systems Integrators (SI) will also benefit from the HyperBatch solution, as they are on the frontlines of converting the existing 250 billion lines of COBOL code from the mainframe to cloud environments. Other vendors that perform ETL and code refactoring in support of legacy migration efforts can leverage the HyperBatch method within their toolsets to bridge the gap when batch processes are the limiting factor.
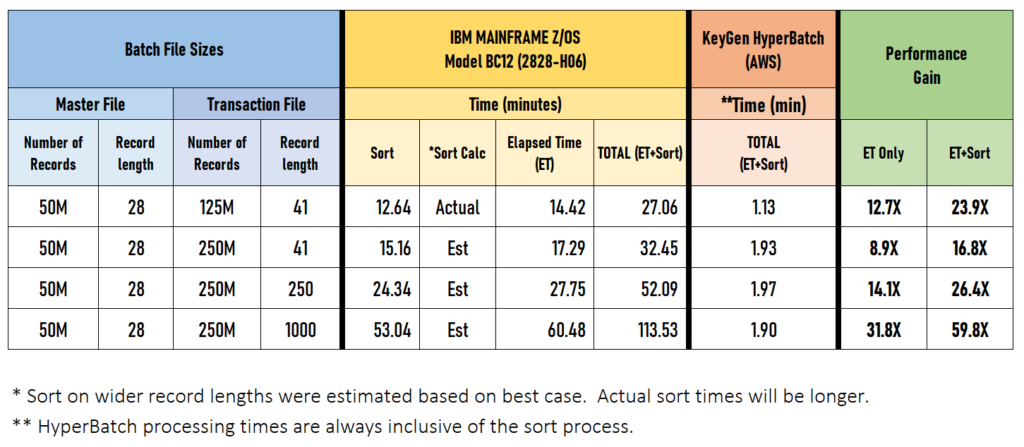
Benchmark tests have been performed, and the result from a typical batch process is presented below for comparison. This is based on a simple COBOL program for a master file/transaction file processing 300 million rows. From this chart, you can see the substantial performance gains realized by the HyperBatch process.
This exciting new concept must be further explored by all players within this field as new products in batch related solutions are now possible by expanding the same concept into other areas of data processing.