Benchmark Test Results
COBOL Batch vs. HyperBatch
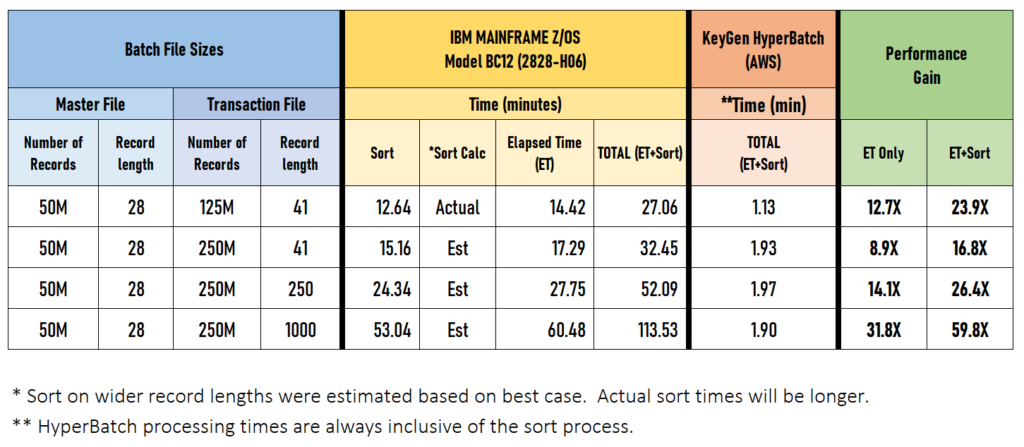
KeyGen Data’s benchmark tests modeled a simple bank statement reconciliation process as a reference. The final results were impressive—HyperBatch achieved the followings:
- Performance gains: 23X to 60X over the mainframe
- Code conversion: 80% reduction in code base (COBOL vs. HyperBatch code)
- Effective cost per transaction: reduced by over 50%
The test was performed using a batch process similar to a bank statement reconciliation process, in which a transaction file with credits and debits updates a master file. The application on the mainframe was written in COBOL and was run on an IBM Model BC12 (2828-H06). The same logic was implemented utilizing the HyperBatch method processed within an Amazon Web Service (AWS) cloud environment. Moreover, since HyperBatch is a process methodology, the same test could have been run in an Azure or Google Cloud environment—or on-premise if required.
Batch Process Test Requirements
Overview
The following test benchmarks a simple COBOL batch process performed on an IBM Mainframe. The COBOL code provided below was developed and run on an IBM Mainframe z/OS system. Sample datasets provided represented approximately 1 billion transaction records against a master file to process.
The objective of this test is to document the performance as represented by the overall time to complete. This includes the time to sort the records, the time to process the batch, and report as independent results.
The following outlines a draft of the program requirements to assist in developing the solution. Please note that the information provided isn’t a complete representation of the solution; rather, it is a starting point to better understand the requirement.
Input/Output FIles
There are two input and two output datasets in the process. Record layouts are given below. Both I/P and O/P have the same layouts. Use the same layouts in 01 under FD and in the working storage as needed. All are fixed block records.
Summary of Business Logic
The following are the rules for the matching logic:
- All account numbers on the master file are unique.
- Transaction files have many transactions for a given account.
- Transactions need to be processed in the order of the date on the transaction records.
- If there is enough balance in the Master file, then process the transaction. Calculate the remaining balance (use a hold balance amount field in working storage) and then apply this balance against the next transaction within the same account.
- If a transaction is processed then put ‘0’ to the TRANS-AMT of the O/P transaction record.
- Use the same rule for all transactions until either no more transactions are left for the account, or their is not enough balance to process any more transactions.
- If there is not enough balance in the account to process a transaction, reject the transaction and move ‘Y’ to REJECT-IND of the TRANS-OUT record, but process the next transaction in the file.
Sorting Requirements
The Master file needs to be sorted on MASTER-ACCT-NUMBER in ascending order. Transaction file must be sorted on both the TRANS-ACCT-NUMBER and TRANS-DATE in ascending order.
SORT must be the first STEP in the JCL for the JOB for executing the COBOL program. We want to get the total time of execution of the JOB including the SORT.